Data Cockpit: Manage & Partition Data for Cloud Processing ✨
Data Cockpit is an interactive Python widget within PyRun designed to streamline data handling for your cloud compute jobs. It lets you select datasets from various sources (your S3, public registries), partition them intelligently using the integrated DataPlug library, and obtain metadata ready for parallel processing frameworks like Lithops.
This guide explains how Data Cockpit simplifies preparing data for distributed workloads.
🚀 Key Features
Dataset Selection
✅ Upload your own data to S3.
✅ Choose an existing dataset in your bucket.
✅ Access public datasets from the AWS Open Registry or Metaspace.Intelligent Partitioning
✅ Use DataPlug to split your dataset into multiple data slices.
✅ Manually set or automatically calculate the batch size.
✅ (Optional) Run a benchmark to find the optimal batch size.Distributed Processing
✅ Integrate with Lithops to process each data slice in parallel.
✅ Supports AWS Lambda, IBM Cloud Functions, and other serverless backends.Slice Metadata
✅ Provides metadata describing how to access and decode each slice.
✅ Can be passed directly to a Lithops function for processing.
🛠️ Architecture & Workflow
The Data Cockpit widget orchestrates the data preparation phase, interacting with S3 and the underlying DataPlug library. The output (slice metadata) feeds directly into the cloud processing phase (e.g., using Lithops).
⚙️ Installation & Prerequisites
- Python 3.10+
- pdal
- laspy
- rasterio
- Data Cockpit.
- DataPlug for partitioning.
- Lithops for cloud processing.
Install the dependencies:
pip install pdal laspy rasterio
pip install cloud-dataplug cloud-data-cockpit lithops📌 Step-by-Step Usage
1️⃣ Configure Data Cockpit
from cloud_data_cockpit import DataCockpit
# Initialize the cockpit
cockpit = DataCockpit()2️⃣ Select Dataset & Adjust Partitioning
Using the Data Cockpit widget, you can:
- Upload a new dataset to S3 to be partitioned by DataPlug.
- Select an existing dataset from your S3 bucket.
- Access public datasets from AWS Open Registry.
- Retrieve datasets from Metaspace.
Widget Interface
Below are different ways to select a dataset using the Data Cockpit interface:
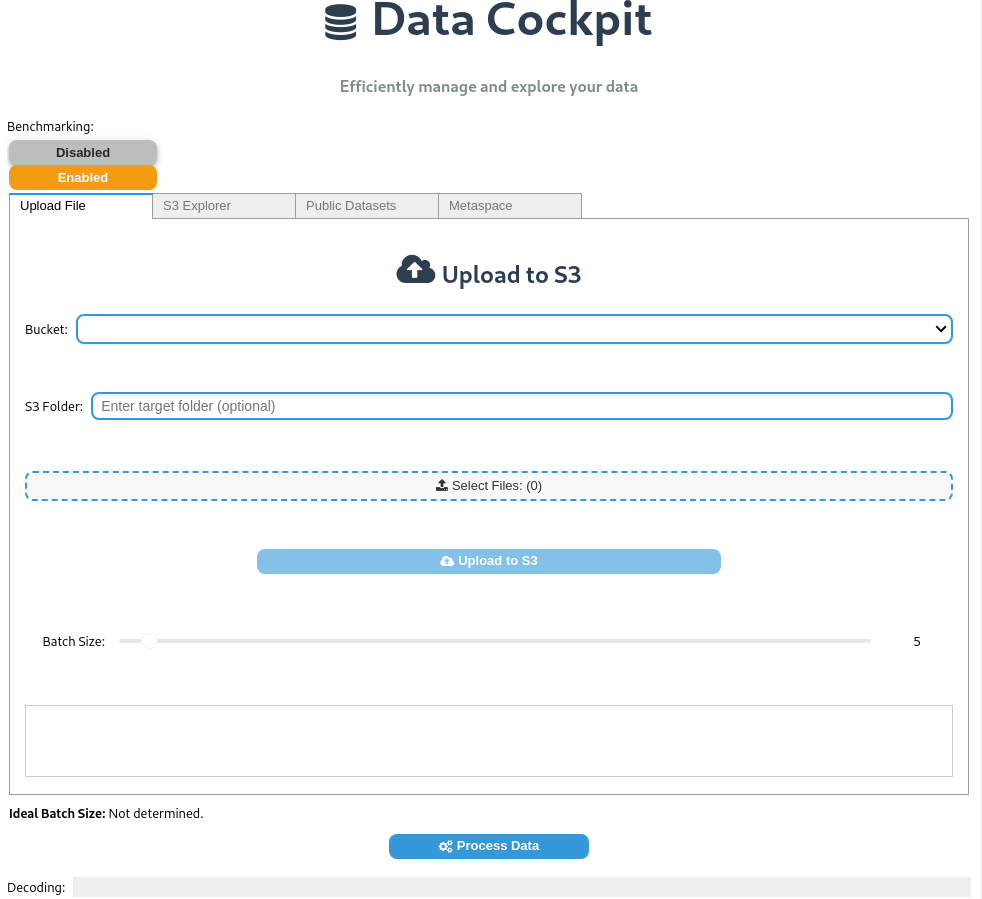
Uploading a dataset to S3: Users can upload local files to their AWS S3 bucket. Once uploaded, DataPlug can partition the dataset for optimized processing.
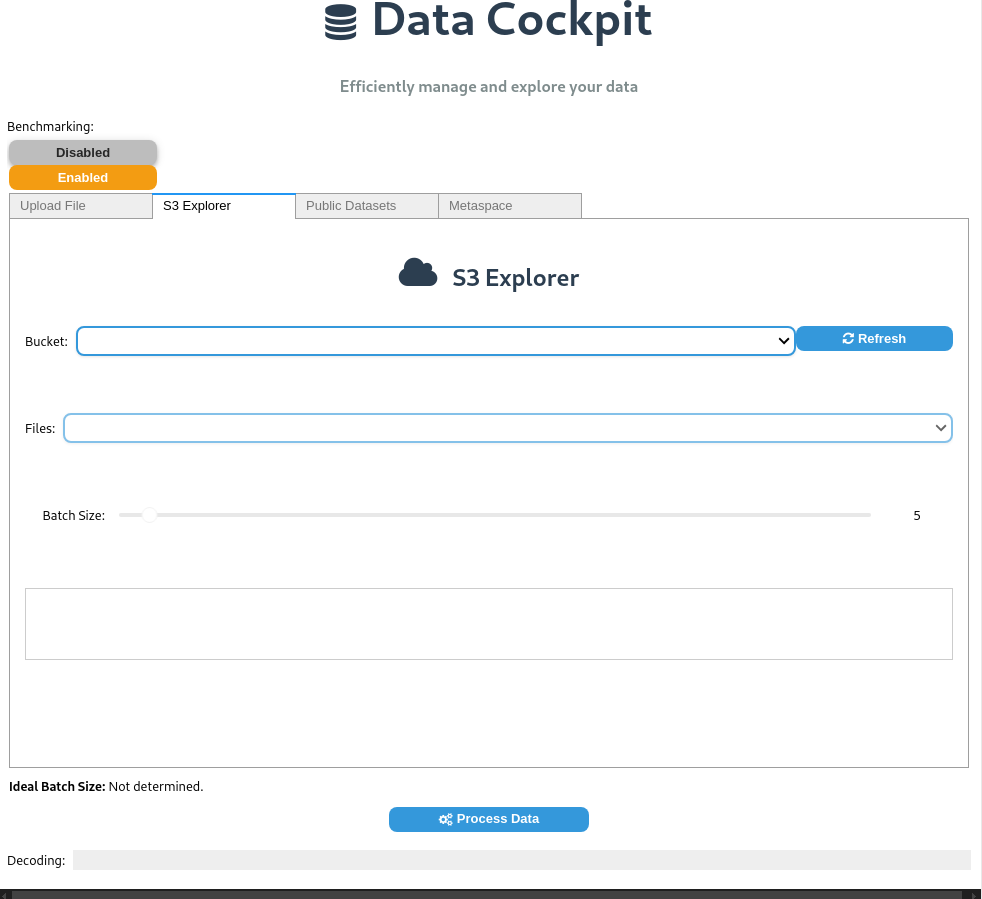
Selecting an existing dataset from S3: Users can browse their S3 storage, select a dataset, and configure partitioning before processing.
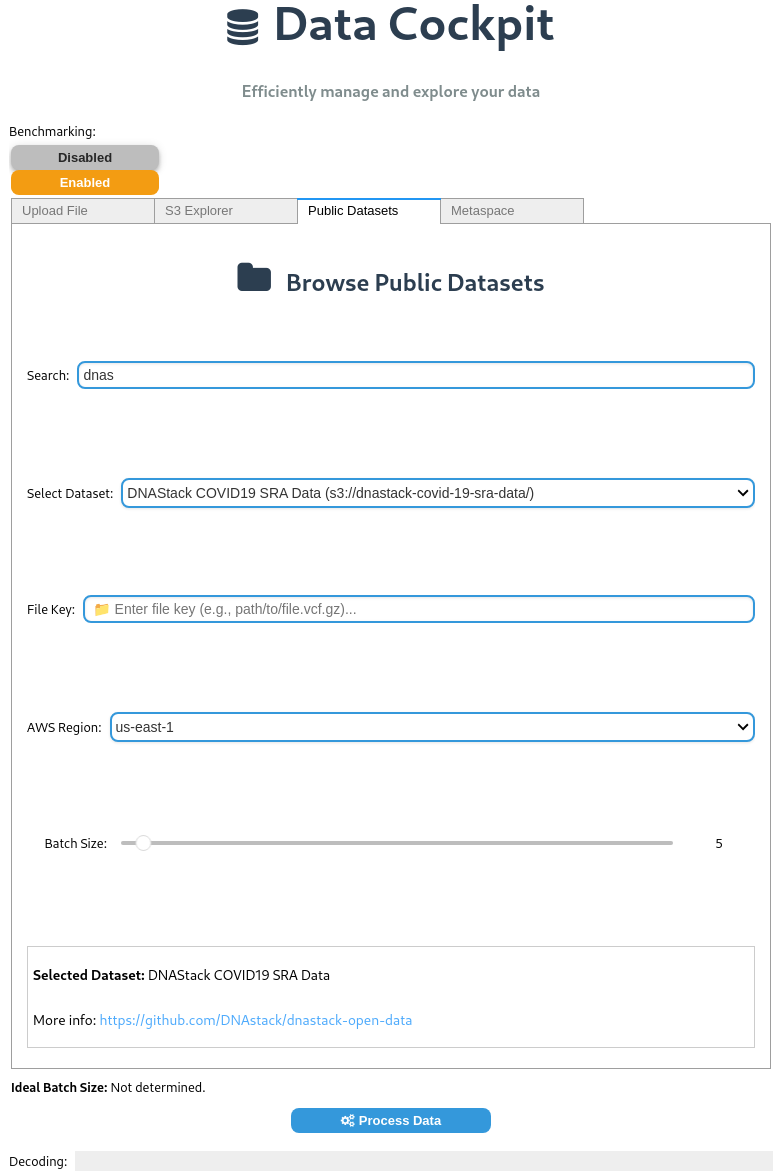
Choosing a dataset from AWS Open Registry: The widget provides access to publicly available datasets from AWS, allowing users to integrate them into their workflows.
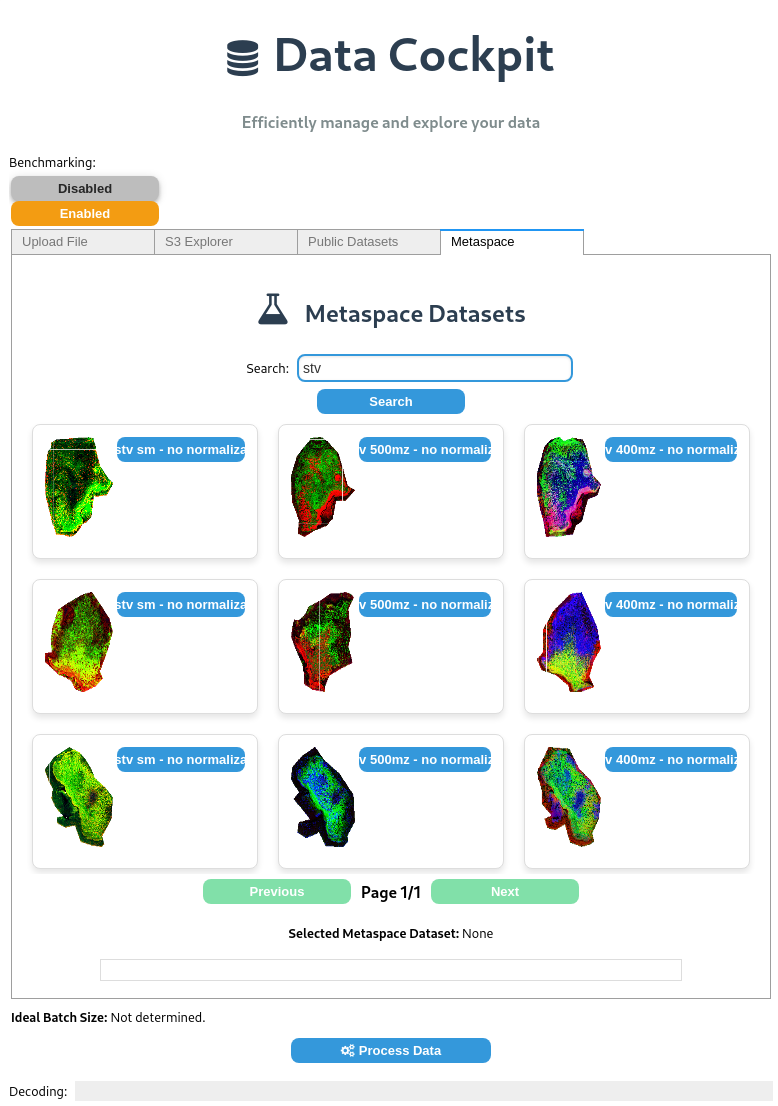
Selecting a dataset from Metaspace: Users can retrieve and process scientific datasets hosted on Metaspace.
Partitioning the Dataset
When selecting a dataset in Data Cockpit, you can manually adjust batch sizes using the Batch Size Slider or enable Benchmarking to automatically determine the ideal batch size based on your dataset and processing function.
In the benchmarking setup (see image below), specify:
- Batch Min – The smallest batch size to test.
- Batch Max – The largest batch size to test.
- Step Size – The increment between each test run.
Benchmarking Configuration: Define the minimum and maximum batch sizes along with the step size.

To activate benchmarking, pass your benchmarking function (benchmarking_fn) to the widget's constructor. This function applies your processing operation across different batch sizes to measure performance.
Example:
cockpit = DataCockpit()Once benchmarking is complete, Data Cockpit automatically adjusts the batch size to the optimal value. This ensures that the selected batch size best fits your dataset and processing function, allowing for efficient data distribution across multiple cloud functions when integrated with Lithops.
3️⃣ (Optional) Provide a Processing Function
If desired, run a benchmark to find the best batch size as explained above. Activate benchmarking by clicking the enabled button to input the min, max, and step values, then click Run Benchmarking.
4️⃣ Integrate with Lithops
import lithops
def process_data_slice(slice_metadata):
# Retrieve and decode the data slice from the provided metadata on the fly.
data_slice = slice_metadata.get()
# Process the data slice (for example, summing a specific column)
return sum(data_slice["column_of_interest"])
slices_metadata = cockpit.get_data_slices()
fexec = lithops.FunctionExecutor()
fexec.map(process_data_slice, slices_metadata)
results = fexec.get_result()
print("Results:", results)🎯 Best Practices
✔️ Optimize Partitioning: Use benchmarking or experiment manually to find a good balance. Too few partitions = less parallelism; too many = high overhead. ✔️ Error Handling: Implement robust error handling within your process_data_slice function. ✔️ Idempotency: Design process_data_slice to be idempotent if possible (running it multiple times on the same slice yields the same result), which helps with retries. ✔️ Resource Matching: Ensure the resources allocated to your Lithops workers (memory, CPU) are sufficient for processing a single slice. Configure this in the PyRun Lithops settings.
💾 Supported Formats (via DataPlug)
DataPlug (the library powering the partitioning) supports various data formats optimized for parallel access. Refer to the DataPlug documentation or the list below for current support. Ensure the format is suitable for chunking/partitioning.
🔬 Use Cases
With this guide, you now have a comprehensive, robust, and efficient workflow to use Data Cockpit with Lithops and DataPlug! 🚀