Pipelines: Real-World PyRun Examples 🧪
PyRun Pipelines are ready-to-run, end-to-end examples demonstrating practical applications of PyRun with frameworks like Lithops and Dask. Instead of building from scratch, launch a pipeline to see PyRun solve a real-world problem, then explore the underlying code and configuration. Pipelines are excellent for learning best practices and discovering PyRun's capabilities.
What are PyRun Pipelines?
Each pipeline represents a complete, pre-configured project:
- Defined Use Case: Addresses a specific task (e.g., performance benchmarking, scientific data analysis, hyperparameter tuning).
- Pre-configured Runtime: Includes all necessary Python packages and dependencies, automatically built by PyRun.
- Ready-to-Run Code: Contains the complete script(s) needed for the task.
- Data Integration: May include sample data or connect to public data sources.
- Automated Execution: PyRun handles launching the job on your AWS account and directing you to monitoring.
- Code Access (Post-Execution): After running, you can typically access the workspace containing the pipeline's code to understand how it works.
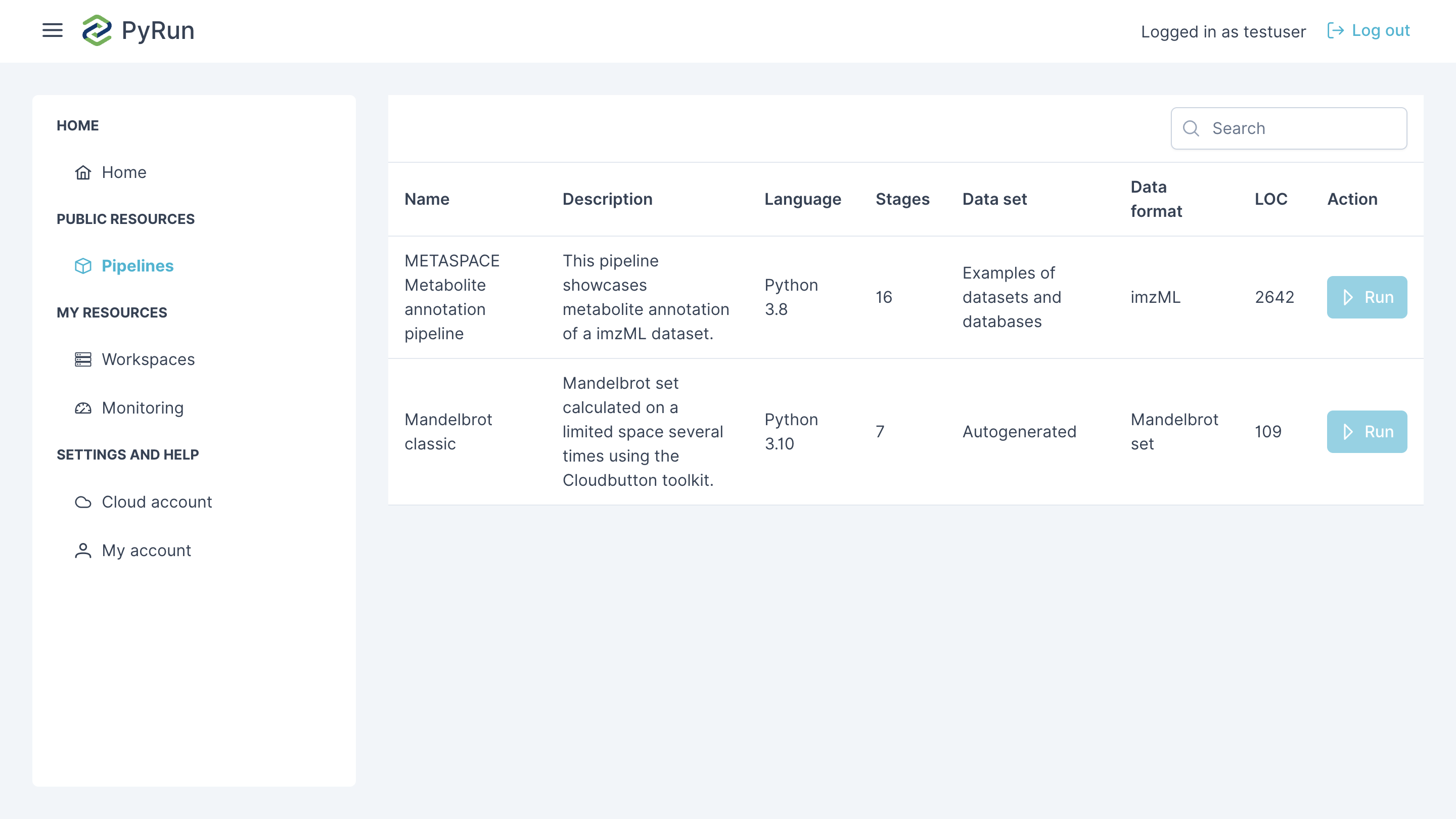
Available Pipelines
Here's a selection of available pipelines:
| Name | Description | Framework Used | Key Concepts Shown | Data Format | Est. Complexity |
|---|---|---|---|---|---|
| Audio Recognition | AI pipeline for audio keyword recognition using TensorFlow. | TensorFlow, NumPy, Matplotlib | Audio recognition, Automatic Speech Recognition (ASR), Spectrogram generation (STFT), CNN, TensorFlow Datasets. | WAV, Spectrogram (derived), TensorFlow Dataset | Medium |
| CMIP6 ECS Estimation (Gregory Method) | Pipeline applying the Gregory method to CMIP6 climate model data to estimate Equilibrium Climate Sensitivity (ECS). | Dask | Climate change model analysis (CMIP6), parallel cloud computing, Gregory method, time series analysis | CSV, Zarr | High |
| CMIP6 Precipitation Frequency Change | Dask pipeline analyzing CMIP6 climate model data to quantify changes in precipitation frequency. | Dask | Climate change model analysis (CMIP6), parallel cloud computing, scientific Data Analysis (xarray) | CSV, Zarr | High |
| Dask | Description for template goes here | Dask (inferred) | N/A | N/A | N/A |
| Dask Machine Learning Example | Demonstrates distributed machine learning using Dask-ML. | Dask, Dask-ML, Scikit-learn, Joblib, Pandas | Distributed machine learning, Hyperparameter tuning (GridSearchCV), Clustering (KMeans). | NumPy arrays, Dask arrays | Medium |
| FLOPS benchmark | Measures floating-point computation performance using parallel functions. | Lithops | Basic map, performance measurement | In-memory tuples | Low |
| Hyperparameter tuning | Performs grid search hyperparameter tuning for a text classification model on Amazon reviews data. | Lithops | ML preprocessing, Grid search, parallel model eval | Compressed text | Medium |
| Image Classification | AI pipeline for image classification using TensorFlow. | TensorFlow, Keras, Matplotlib, NumPy, PIL | Image classification, CNN, TensorFlow, Data Augmentation, Overfitting mitigation. | JPG, TensorFlow Dataset | Medium to High |
| Kerchunk | Generate Kerchunk references from remote NetCDF files, enabling virtual dataset access via xarray. | Dask | Parallel Metadata Generation, dataset Aggregation, scientific Data Analysis (xarray) | NetCDF, Zarr (virtual) | Medium |
| Lithops | Description for template goes here | Lithops (inferred) | N/A | N/A | N/A |
| Lithops TeraSort Benchmark | Serverless pipeline to generate and sort large synthetic datasets using TeraGen and TeraSort over Lithops. Executes a distributed MapReduce-style sort across cloud functions. | Lithops, Polars, NumPy | Serverless parallel data generation, distributed sorting, multipart upload to object storage, map-reduce orchestration, warm-up strategy, function runtime tuning. | Plain text (ASCII) or binary records; output stored in object storage (e.g. S3); optional multipart files | Medium |
| LLM Execution with Ollama | AI Interactive notebook to run Large Language Models (LLMs) locally using Ollama. | Ollama | Local LLM execution, Ollama integration, Interactive prompting, Streaming API, Model management. | Text (user prompts, LLM responses) | Low to Medium |
| Mandelbrot classic | Generates the Mandelbrot set fractal using parallel computation across a defined space. | Lithops | Parallel computation, image generation (map) | Numerical Grid | Medium |
| METASPACE Metabolite annotation pipeline | This pipeline showcases metabolite annotation of a imzML dataset. | Lithops | Multi-step workflow, complex data handling, imzML | imzML, Databases | High |
| Model calculation | This notebook contains a model calculation process that consumes laz files. | Python 3.10 (from language) | LIDAR tiles processing, .laz format (from dataSet, dataFormat) | .laz | N/A |
| NDVI Temporal Change Detection Pipeline | Serverless pipeline to compute NDVI and its change over time using Sentinel-2 imagery. | Lithops, Rasterio, Matplotlib | NDVI calculation, temporal analysis, geospatial image tiling, parallel processing, change detection. | GeoTIFF (S2 bands), JPG (NDVI visualization), S3 paths | Medium to high |
| Vorticity Workload with Cubed | Serverless pipeline for computing and analyzing vorticity using synthetic oceanographic velocity fields with Cubed. | Cubed, Xarray, Zarr, NumPy | Lazy computation, first-order derivatives, chunked ND-array processing, map-overlap optimization, Zarr storage | Zarr (input/output), NumPy arrays | Medium |
| Water consumption | Serverless pipeline that estimates evapotranspiration using DTMs and meteorological data. | Lithops, GRASS GIS, Rasterio | Distributed geospatial processing, IDW interpolation, solar radiation modeling, evapotranspiration. | GeoTIFF, CSV (SIAM), ZIP (shapefile) | Medium to high |
Running a Pipeline
Navigate to Pipelines: Find "Pipelines" in the PyRun sidebar.
Browse: Review the available pipelines and their descriptions.
Select & Launch: Click the "Run" button for the desired pipeline.
Monitor: PyRun automatically initiates the execution on your AWS account and shows you the Real-Time Monitoring page for that job. Watch the logs and metrics.
Exploring Pipeline Code
- Access Workspace: Once a pipeline execution is complete (or sometimes even while running, depending on implementation), PyRun usually provides a link or way to open the associated Workspace.
- Examine Files: Inside the workspace, you'll find the Python scripts (
.py), runtime definition (.pyrun/environment.yml), and any other configuration files used by the pipeline. - Learn: Study how the code utilizes Lithops or Dask, how data is handled, and how the workflow is structured. This is a great way to learn practical techniques.
Benefits of Using Pipelines
- Learn by Doing: See concrete examples of how PyRun works for real tasks.
- Quick Evaluation: Assess PyRun's suitability for different types of problems without initial coding effort.
- Best Practices: Observe effective patterns for structuring cloud-based Python applications.
- Code Templates: Adapt code snippets or entire structures from pipelines for your own projects.
- Discover Features: See integrations like Data Cockpit or specific framework features in action.
More Pipelines Coming!
We are continuously developing and adding new pipelines covering more domains (like advanced ML, geospatial analysis, genomics) and showcasing more PyRun features and framework integrations. Check back often!
Start exploring PyRun Pipelines today and accelerate your journey into effortless cloud computing!